


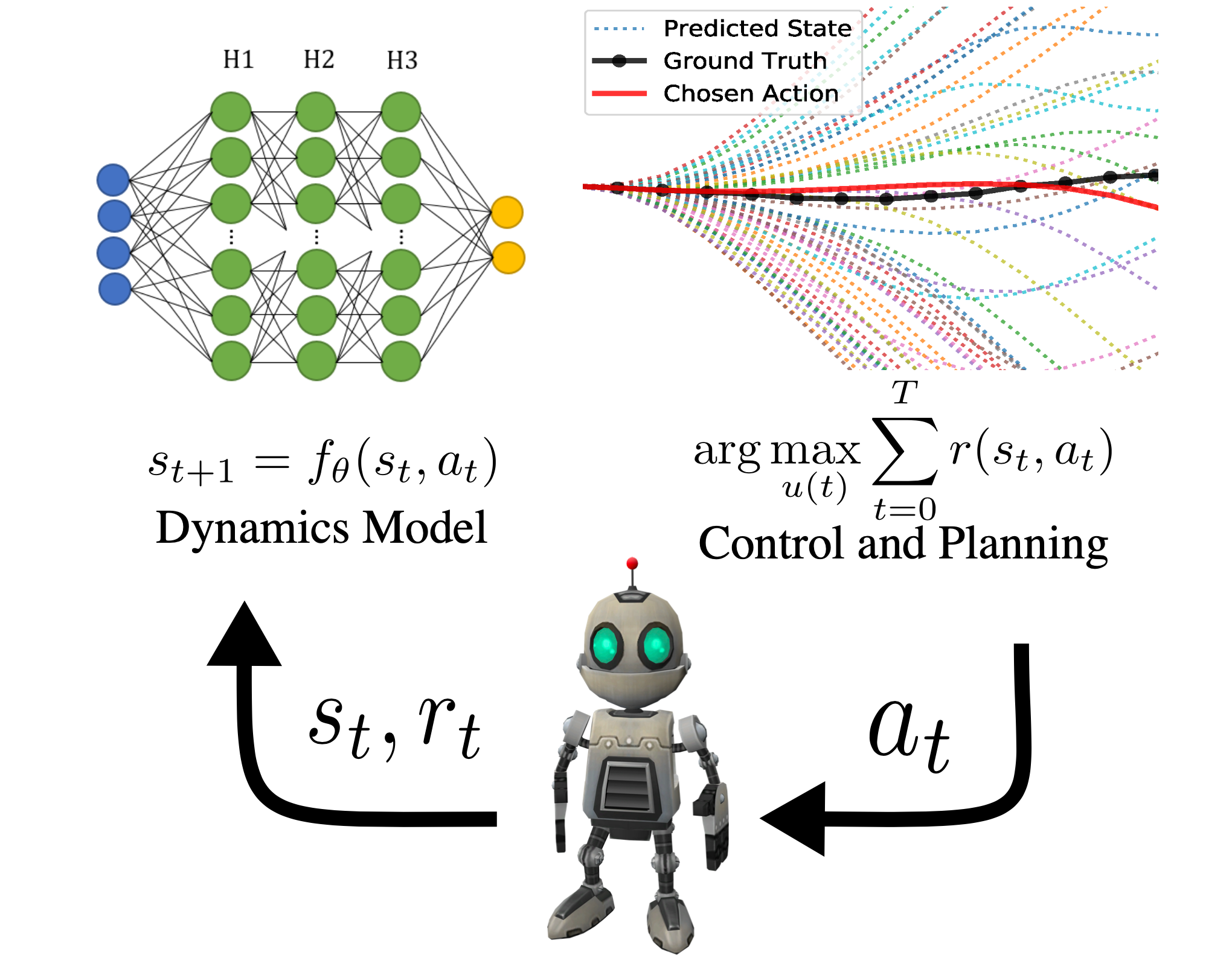
Model-based reinforcement learning (Source: https://bair.berkeley.edu/blog/2021/04/19/mbrl/)
Understanding the link between independent and dependent variables is fundamental to machine learning. Exploratory Data Analysis and feature engineering consume a significant amount of time while working on machine learning projects. Tuning hyperparameters is another important component of model building.
The goal of hyperparameter tuning is to fine-tune the hyperparameters so that the machine can build a robust model that performs well on unknown data. Effective hyperparameter adjustment, in conjunction with excellent feature engineering, may considerably improve model performance. While many sophisticated machine learning models, such as Bagging (Random Forests) and Boosting (XGBoost, LightGBM, and so on), are already optimised with default hyperparameters, there are times when hand tweaking might improve model outputs.
Parameters vs Hyperparameters
In machine learning, understanding the distinction between parameters and hyperparameters is critical. Let's look at the fundamental distinctions between these two ideas.
What is a Parameter in Machine Learning?
In machine learning models, parameters are the variables that the model learns from available data during the training phase. They have a direct impact on the model's performance and represent the model's internal state or features. Typically, parameters are optimised by altering their values using an optimisation process such as gradient descent.
In a linear regression model, for example, the parameters are the coefficients associated with each input feature. Based on the data supplied, the model learns these coefficients, seeking to discover the optimal values that minimise the gap between the expected and actual output.
The parameters of Convolutional Neural Networks (CNNs) are the weights and biases associated with the network's layers. These parameters are repeatedly modified during training using backpropagation and optimisation approaches such as stochastic gradient descent.
Parameters, in summary, are intrinsic to the model and are learnt from data during training.
What is a Hyperparameter?
The model's setup or settings are defined by hyperparameters. They are not learnt from data, but rather provided as inputs prior to training the model. The learning process is guided by hyperparameters, which influence how the model performs during training and prediction.
Machine learning engineer(s) and/or researcher(s) working on a project establish hyperparameters depending on their experience and domain knowledge. It is critical to tune these hyperparameters in order to improve the model's performance and generalisation ability.
Learning rate, batch size, number of layers, filter sizes, pooling algorithms, dropout rates, and activation functions are examples of hyperparameters in computer vision. These hyperparameters are chosen depending on the features of the dataset, the difficulty of the job, and the computational resources available.
The model's performance in computer vision tests can be significantly improved by fine-tuning hyperparameters. Adjusting the learning rate, for example, can alter convergence speed and keep the model from being trapped in poor solutions. Similarly, adjusting the number of layers and filter sizes in a CNN might affect the model's capacity to capture complex visual patterns and features.
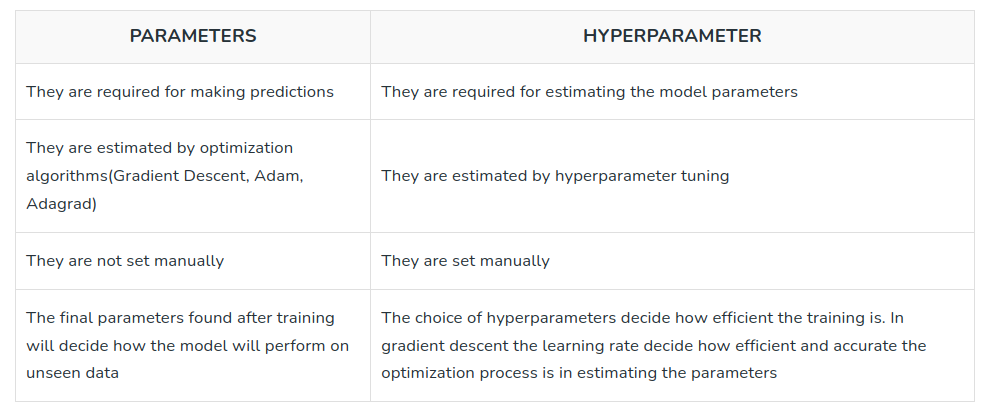
The table above summarizes the difference between model parameters and hyperparameters. (Source: https://www.geeksforgeeks.org/difference-between-model-parameters-vs-hyperparameters/)
Common Computer Vision Hyperparameters
Various hyperparameters have a major influence on the performance and behaviour of machine learning models in computer vision applications. Understanding and tweaking these hyperparameters correctly may significantly improve the accuracy and efficacy of computer vision applications. Here are some examples of frequent hyperparameters in computer vision:
- Learning rate: The learning rate defines how frequently the model's parameters are updated during training. It has an impact on the training process's convergence speed and stability. It is critical to find an ideal learning rate in order to avoid underfitting or overfitting.
- Batch size: The batch size defines how many samples are handled in each iteration of model training. It has an impact on the model's training dynamics, memory needs, and generalisation ability. Choosing an appropriate batch size is determined by the computing resources available as well as the features of the dataset on which the model will be trained.
- Network architecture: The structure and connection of neural network layers are defined by network architecture. It specifies the number of layers, their kind (convolutional, pooling, completely linked, and so on), and their configuration. The intricacy of the job and the available processing resources influence the choice of network design.
- Kernel size: The kernel size of convolutional neural networks (CNNs) influences the receptive field size utilised for feature extraction. It has an impact on the model's degree of detail and geographical information. To balance local and global feature representation, the kernel size must be tuned.
- Dropout rate: Dropout is a regularization technique that randomly drops a fraction of the neural network units during training. The dropout rate determines the probability of “dropping” each unit. Dropout rate helps prevent overfitting by encouraging the model to learn more robust features and reduces the dependence on specific units.
- Activation functions: Non-linearity is introduced into the model through activation functions, which define the output of a neural network node. ReLU (Rectified Linear Unit), sigmoid, and tanh are examples of common activation functions. Choosing the right activation function can affect the model's ability to capture complicated interactions as well as its training stability.
- Data augmentation: Data augmentation techniques like as rotation, scaling, and flipping increase the training dataset's richness and unpredictability. Data augmentation hyperparameters such as rotation angle range, scaling factor range, and flipping probability impact the augmentation process and can increase the model's capacity to generalise to previously unknown data.
- Optimization algorithm: The optimisation algorithm used affects the model's convergence speed and stability throughout training. Optimisation methods that are commonly used include stochastic gradient descent (SGD), ADAM, and RMSprop. The optimisation algorithm's hyperparameters, such as momentum, learning rate decay, and weight decay, can have a substantial influence on the training process.
To obtain the ideal values for a given computer vision job, tuning these hyperparameters needs rigorous testing and analysis. To attain the best results, trade-offs between computing resources, dataset properties, and model performance must be considered.
How to Adjust Hyperparameters
Manual Hyperparameter Tuning
Manual hyperparameter tuning is a way of manually modifying the hyperparameters of a machine learning model. It entails adjusting the hyperparameters iteratively and assessing the model's performance until suitable results are obtained. Although this may be a time-consuming operation, manual tuning allows you to experiment with different hyperparameter combinations and tailor them to specific datasets and applications.
Consider a support vector machine (SVM) model as an example. The choice of kernel (linear, polynomial, or radial basis function), the regularisation parameter (C), and kernel-specific parameters (such as degree for a polynomial kernel or gamma for an RBF kernel) are among the hyperparameters that may be manually set. The ideal combination for the individual problem may be established by experimenting with different values for these hyperparameters and assessing the model's performance using relevant metrics.
Hyperparameter Tuning with Grid Search
Grid search entails extensively scanning a given set of hyperparameter variables for the optimal combination of performance. A grid search examines the hyperparameter space methodically by building a grid or a Cartesian product of all potential hyperparameter values and assessing the model for each combination.
In grid search, the range of values for each hyperparameter that has to be tweaked must be defined. The grid search technique then trains and assesses the model using all possible values combinations. To find the optimal collection of hyperparameters, the performance metric, such as accuracy or mean squared error, is employed.
Take, for example, a Random Forest classifier. Grid search may be used to modify hyperparameters such as the number of trees in the forest, the maximum depth of each tree, and the minimum amount of samples necessary to split a node. Grid search investigates all conceivable combinations (e.g., 100 trees with a maximum depth of 5, 200 trees with a maximum depth of 10, etc.) by specifying a grid of values for each hyperparameter, such as [100, 200, 300] for the number of trees and [5, 10, 15] for the maximum depth. For each combination, the model is trained and assessed, and the best-performing collection of hyperparameters is chosen.
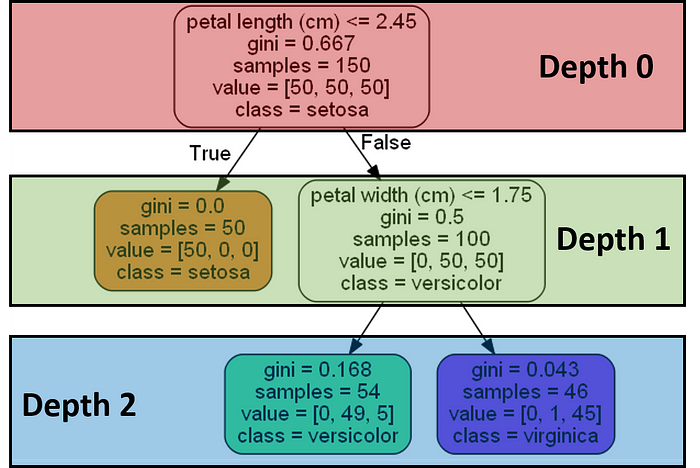
In a decision tree, one of the main hyperparameters is the depth of the tree and the number of samples in each leaf. (Source: https://medium.com/analytics-vidhya/hyperparameter-tuning-8ca311b16057)
Hyperparameter Tuning with Random Search
Unlike grid search, which examines all potential possibilities exhaustively, random search samples at random from a preset range of hyperparameter values. This sampling procedure enables more efficient and scalable hyperparameter space exploration.
In grid search, the range of values for each hyperparameter that has to be tweaked must be defined. A random search, on the other hand, defines the distribution or range of values for each hyperparameter that has to be tweaked. The random search method then selects hyperparameter value combinations from these distributions and evaluates the model's performance. Random search attempts to determine the optimum hyperparameter settings by iteratively sampling and analysing a given number of options.
Consider the gradient boosting machine (GBM) model. The learning rate, maximum depth of the trees, and subsampling ratio are all hyperparameters that may be modified via random search.
Random search, as opposed to defining a grid of values, allows the engineer to define probability distributions for each hyperparameter. For example, a uniform distribution with a range of 0.01 to 0.1 for the learning rate, a discrete distribution with a range of 3 to 10, and a normal distribution with a range of 0.8 for the subsampling ratio. The random search method then picks hyperparameter combinations at random and analyses the model's performance for each combination.
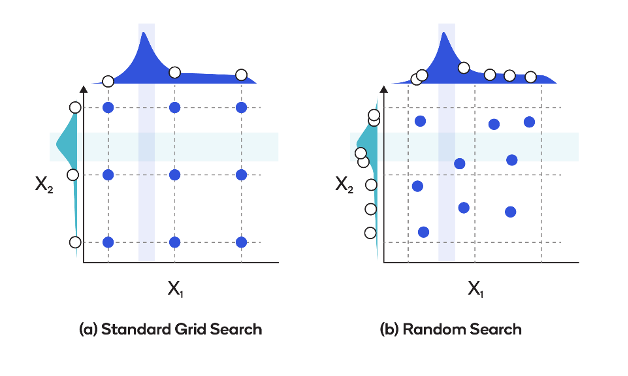
Random search vs grid search
Hyperparameter Tuning with Bayesian Optimization
Bayesian optimisation use probabilistic models to efficiently find the best hyperparameters. This works by examining a small number of configurations progressively depending on their projected usefulness.
In Bayesian optimisation, a probabilistic model, such as a Gaussian process, is used to estimate the behaviour of the objective function. As new configurations are examined, this model is updated to capture the links between hyperparameters and performance. The model is then used to direct the search process and choose the next set of hyperparameters to assess, with the goal of optimising the objective function.
Take, for example, a deep neural network model. Bayesian optimisation may be used to fine-tune hyperparameters such as learning rate, dropout rate, and hidden layer count. The starting configurations are chosen at random. The programme automatically picks new configurations to assess when the surrogate model is updated based on the projected gain in performance. Because of this iterative approach, Bayesian optimisation can effectively search the hyperparameter space and select the values that produce the greatest model performance.
Hyperparameter Tuning with Bayesian Optimization in Computer Vision
Bayesian optimisation is very useful for hyperparameter adjustment in computer vision problems. Several instances of Bayesian optimisation in computer vision are shown below:
- Image style transfer: Bayesian optimisation may be used to modify hyperparameters such as the content weight, style weight, and number of iterations in picture style transfer using neural networks. The model represents the link between hyperparameters and measures such as perceptual and style loss. The search procedure is guided by Bayesian optimisation to uncover hyperparameter values that result in aesthetically attractive stylized pictures.
- Image recognition: Bayesian optimisation may be used to optimise hyperparameters for CNN-based image recognition applications. This method may be used to optimise hyperparameters such as learning rate, weight decay, and batch size. The model accurately represents the model's performance, and Bayesian optimisation intelligently searches the hyperparameter space to find the combination that maximises recognition performance.
- Image generation: To optimise hyperparameters in image generating jobs utilising VAEs, Bayesian optimisation can be used. It is possible to optimise hyperparameters such as the latent space dimension, learning rate, and batch size. The model measures reconstruction loss and generation quality, which may be used in conjunction with Bayesian optimisation to discover hyperparameter values that result in higher-quality generated images.
Bayesian optimisation provides an efficient strategy for hyperparameter tweaking in computer vision by utilising probabilistic models and intelligent exploration. It enables fast navigation of the hyperparameter space and aids in the identification of optimal hyperparameter configurations, resulting in enhanced performance and better results in a variety of computer vision applications.
Conclusion
Tuning hyperparameters is an important step in constructing accurate and resilient machine learning models. Popular strategies for exploring the hyperparameter space include manual tuning, grid search, random search, and Bayesian optimisation.
Each approach has its own set of pros and disadvantages. Machine learning practitioners search for the best settings for a particular model. The optimal strategy is determined by parameters such as the size of the search space and computer resources.
These strategies are critical in the field of computer vision for improving performance and generating better results.
By utilising these strategies successfully, practitioners may optimise their models and realise the full potential of their computer vision applications.
Learn more about SKY ENGINE AI offering
To get more information on synthetic data, tools, methods, technology check out the following resources:
- Telecommunication equipment AI-driven detection using drones
- A talk on Ray tracing for Deep Learning to generate synthetic data at GTC 2020 by Jakub Pietrzak, CTO SKY ENGINE AI (Free registration required)
- Example synthetic data videos generated in SKY ENGINE AI platform to accelerate AI models training
- Presentation on using synthetic data for building 5G network performance optimization platform
- Working example with code for synthetic data generation and AI models training for team-based sport analytics in SKY ENGINE AI platform


