


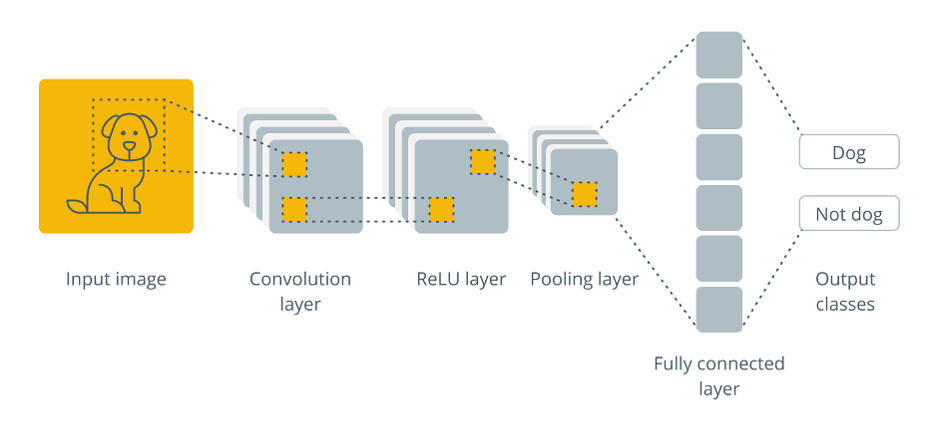
Convolutional Neural Network (CNN) example (Source: https://cointelegraph.com/explained/what-are-convolutional-neural-networks)
The use of several hidden layers in machine learning (referred to as "deep learning") has outperformed traditional strategies for solving a variety of problems, notably in pattern recognition and object detection. The Convolutional Neural Network (CNN) is a prominent deep learning architecture that is widely used for classification tasks.
CNNs have played an important part in computer vision, which tries to educate machines to analyse visual input. AlexNet, named after its principal developer, Alex Krizhevsky, was established in 2012 by a team of academics from the University of Toronto. This model outperformed the runner-up in the ImageNet computer vision contest by achieving an astonishing 85% accuracy in image recognition.
AlexNet's success was partly due to the usage of CNNs, a form of neural network that replicates how humans see. CNNs have become a crucial component of many computer vision applications over the years, and they are now a frequent topic in online computer vision courses. Understanding the operation of CNNs and the CNN algorithm in deep learning is thus critical for everyone interested in this topic.
What is a Convolutional Neural Network?
A CNN is a deep learning architecture that receives an image, applies convolutions and pooling, and then passes it through a fully-connected layer and activation function to generate an output. This output often provides a categorization for an image's contents or information about the location of various objects in an image.
CNNs use a method known as convolution, as opposed to classic neural networks, which depend mostly on matrix multiplications. Convolution is a mathematical procedure that combines two functions to produce a third function that shows how one function alters the form of the other. To return a prediction, further processing stages occur, including pooling and passing via fully-connected layers and an activation function. A typical CNN architecture is shown below.
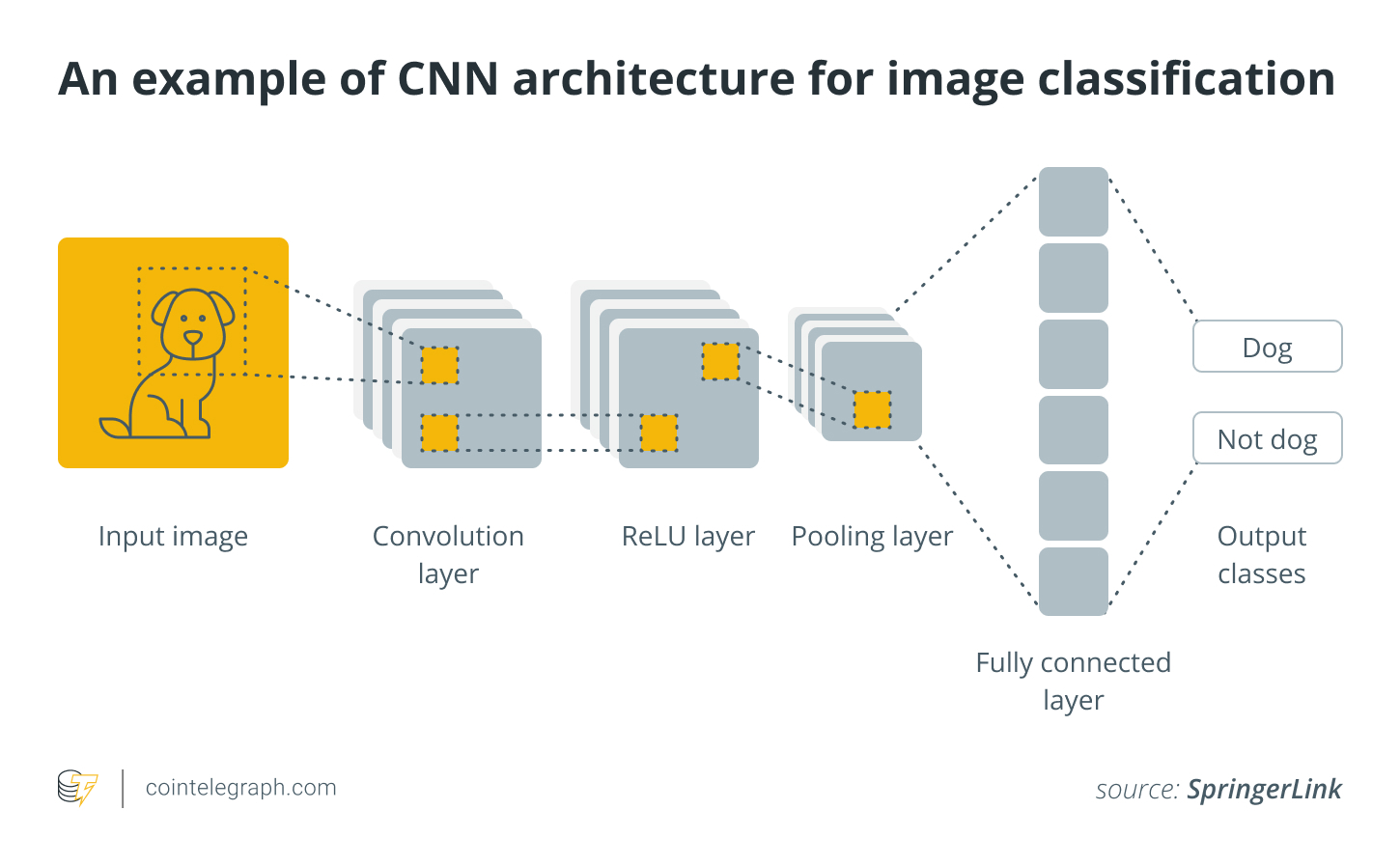
Convolutional Neural Network Architecture (Source: https://www.analyticsvidhya.com/blog/2020/10/what-is-the-convolutional-neural-network-architecture/)
Through the process of convolution, the convolutional layers of a CNN efficiently scan the image and extract essential properties such as edges, textures, and forms. These characteristics are then transferred through numerous layers and processed with techniques like pooling and activation functions, resulting in a compact but informative representation of the original picture. This compact representation is subsequently sent into the network's fully linked layers, which make the final predictions.
While understanding the mathematical subtleties of convolution is beneficial, it is not required to comprehend the broad notion of a CNN.
A CNN is meant to take in an image and turn it into a representation that a neural network can understand, while retaining crucial elements that will allow accurate predictions.
CNNs vs. Feed-Forward Neural Nets
To fully appreciate CNNs in context, examine their forefathers: feed-forward neural networks.
A feedforward neural network is a form of neural network that analyses data in a single pass by passing the input through numerous layers before reaching the output. When it comes to image processing, feedforward networks have a significant limitation: the potential of corruption.
An picture can be represented as a number matrix with the dimensions (rows * columns * number of channels). A typical real-world image would have a resolution of at least 200 * 200 * 3. One method for sending an image into a feedforward neural network is to flatten it into a 1D matrix. However, this would need a huge number of neurons and weights in the first hidden layer. This results in a high number of parameters, increasing the danger of overfitting.
Convolutional neural networks, on the other hand, take a different approach to image processing. CNNs traverse through the entire image while processing small patches at a time rather than flattening the image and analysing it all at once. By doing so, the network may learn the image's key properties while employing fewer neurons and parameters. CNNs are more effective and less prone to overfitting as a result of this method than feedforward neural networks.
How Do Convolutional Neural Networks Work?
It's crucial to comprehend the fundamentals of images and how they are represented before delving into the inner workings of convolutional neural networks.
A matrix of pixel values, with each pixel having a unique colour value, can be used to represent an image. The Red, Green, and Blue colour channels are each represented by one of three planes in RGB pictures, the most popular sort of image. Contrarily, there is only one plane in a grayscale image. The pixel's intensity is represented by this plane.
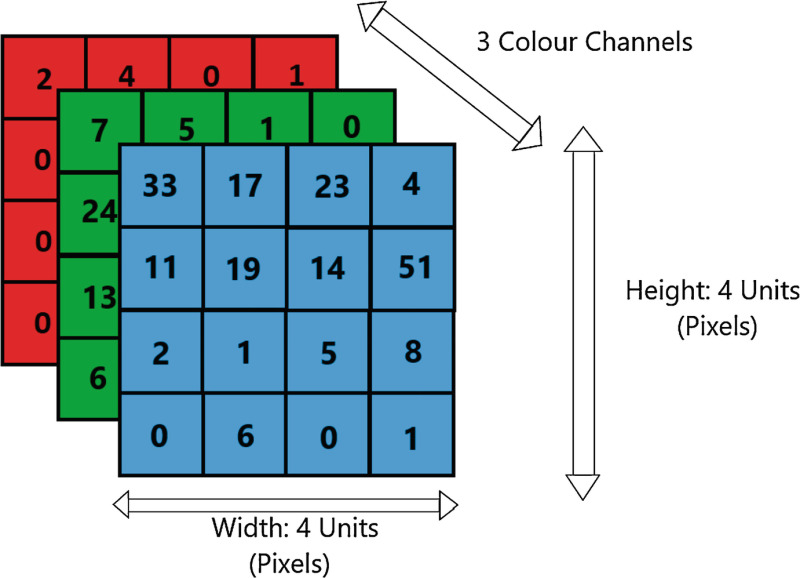
A 3D tensor of a Red-Green-Blue (RGB) image of a dimension of 4 × 4 × 3 (Source: https://www.ncbi.nlm.nih.gov/books/NBK583959/figure/ch13.Fig2/)
An image's resolution is determined by the number of pixels in it; a higher resolution image has more pixels and, as a result, more detailed information.
But how CNNs operate? Given that grayscale images' structure is less intricate than that of RGB images, let's go through an example employing them.
What is a Convolution?
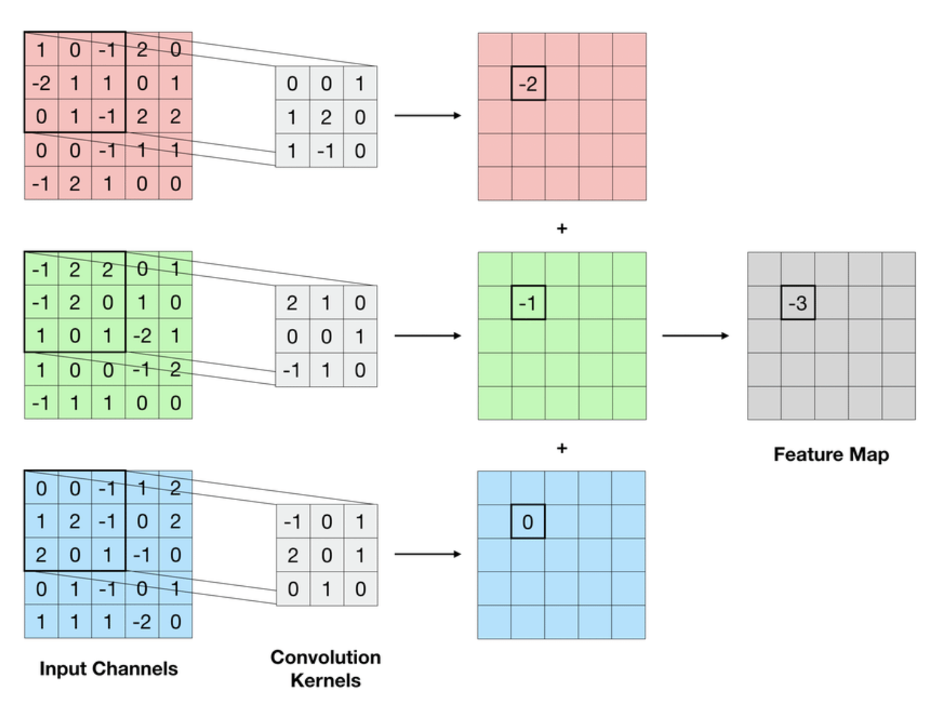
The first step in the convolution of a 5 × 5 × 3 image by a single 3 × 3 filter. For each channel of the input, we compute a sum of the highlighted pixel values weighted by the corresponding values in the convolution kernel. The channel-wise results are then summed up to produce the indicated entry in the output feature map. The remaining values of the feature map are populated by sliding the kernel over the input and repeating the computation. Zero-padding is utilized along the edges of the input to ensure that the operation remains well-defined even when parts of the kernel are out of bounds. A convolutional layer comprises many such filters, each of which produces its own feature map. The weights of the kernels are determined by the learning process. (Source: https://www.researchgate.net/publication/328494567_Machine_Learning_Methods_for_Track_Classification_in_the_AT-TPC)
A convolution is a technique used to extract key features from an input image by applying a tiny matrix, also referred to as a filter or kernel. Moving the filter across the image causes the values at each place to be multiplied by the corresponding values in the image, with the results being added together.
A "convolved feature" is created as a result of this procedure, and it is then forwarded to the following layer for additional processing. Here is an animation showing the procedure being used on a 5x5 pixel grid:
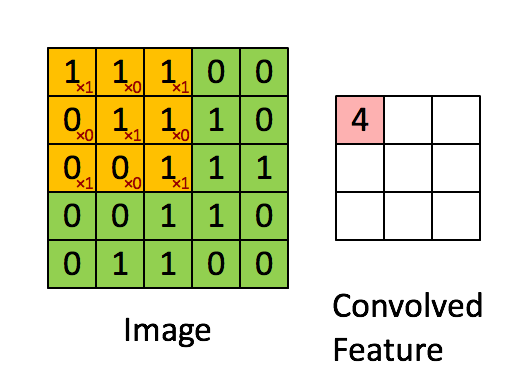
How convolution works. (Source: https://glassboxmedicine.com/2020/08/03/convolutional-neural-networks-cnns-in-5-minutes/)
Artificial "neurons" are arranged in a number of interconnected layers that make up convolutional neural networks. These computer-generated neurons are mathematical operations that receive various inputs, weigh them, and then output an activation value.
The ConvNet's initial layer is in charge of recognising fundamental features like edges, corners, and other straightforward forms. The network uses the knowledge gained from earlier layers to build upon its ability to detect more complex characteristics, such objects and faces, as the image is transmitted through succeeding layers. Further processing of the image by the network enables it to recognise even more intricate elements, including faces, objects, and other features.
An "activation map" is produced by the final convolution layer of a convolutional neural network. This map is used by a classification layer, for instance, to assess the likelihood that an input image belongs to a particular "class" in classification tasks.
A series of confidence scores with values ranging from 0 to 1 are used to express this likelihood. The final layer's output, for instance, can be the likelihood that the input image contains one of the cats, dogs, or horses that the ConvNet is trained to recognise. The likelihood that the image contains the specified class increases with the value.
CNNs in Object Detection
CNNs can be used to locate and recognise things in an image or video, a technique known as object detection. In this scenario, the output of a CNN would be a set of bounding boxes around the items in the image, along with class labels and confidence scores identifying each object's class and the network's level of confidence in its predictions.
The R-CNN (Regions with Convolutional Neural Networks) family of models, which is well-known, is a frequent example of a two-stage framework for using CNNs for object detection. First, prospective object regions in the image are proposed by the network, also known as "region proposals".
A fully connected network is utilised to categorise the items in the regions and improve the bounding boxes in a second step once these region recommendations are analysed. Recent techniques, such as YOLO (You Only Look Once) and RetinaNet, employ a one-stage approach in which the network predicts the bounding boxes, class labels, and confidence ratings from the input picture in a single pass. These models are often quicker than two-stage techniques, but have significantly poorer accuracy.
The primary concept behind utilising CNNs for object recognition, regardless of the exact architecture, is to utilise the convolutional layers to extract rich, discriminative features from the image, and then use these features to create predictions about the items in the image.
Layers in Convolutional Neural Networks
Pooling Layer
The Pooling layer, like the Convolutional Layer, lowers the spatial scale of the convolutional neural network's convolved features.
The spatial size is reduced by downsampling the convolved features. This accomplishes two goals: it reduces the processing power necessary to process the data while simultaneously improving the level of abstraction in the features.
In CNNs, two types of pooling algorithms are often used: average pooling and maximum pooling.
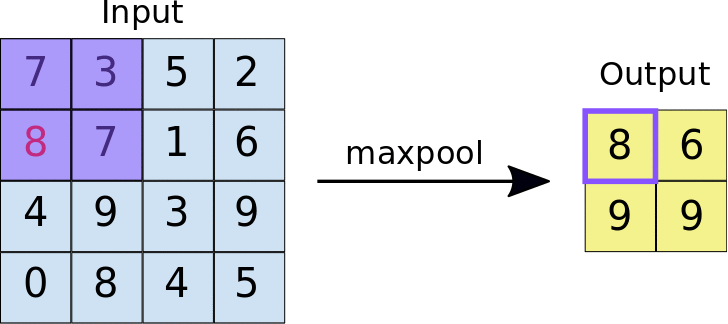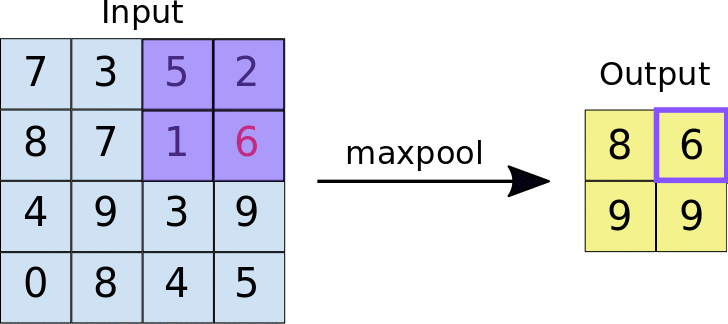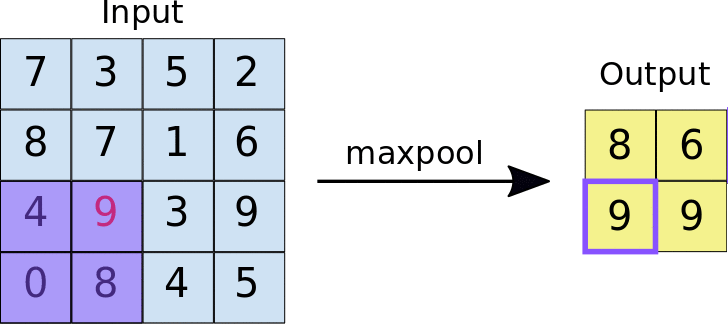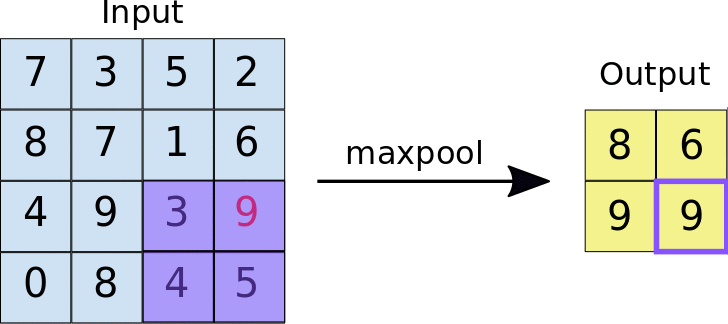
Max pooling performed over a 4x4 feature map with a 2x2 filter and stride of 2 and the output of the max pooling operation. Note the resulting feature map is now 2x2, preserving only the maximum values from each tile. (Source: https://developers.google.com/machine-learning/practica/image-classification/convolutional-neural-networks)
By downsampling, Max pooling decreases the spatial size of the convolved features. It operates by picking the maximum value of a pixel from the kernel-covered region of the picture.
This approach not only minimises the processing power required to interpret the data, but it also acts as a noise suppressor, rejecting noisy activations and performs de-noising while also reducing dimensionality.
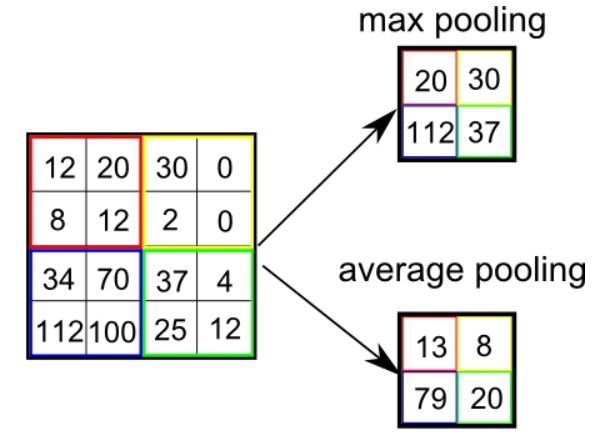
The outputs of max pooling and average pooling omparison (Source: https://poojamahajan5131.medium.com/max-pooling-210fc94c4f11)
Activation Function Layer
The layer of activation function assists the network in learning non-linear correlations between input and output. It is in charge of adding non-linearity into the network and helping it to simulate complicated data patterns and connections.
Typically, the activation function is applied to the output of each neuron in the network. It takes the weighted total of the inputs and generates an output, which is then passed on to the next layer.
The following are the most often used activation functions in CNNs:
- Rectified linear unit (ReLU)
- Sigmoid
- Hyperbolic tangent (tanh)
Because it is computationally inexpensive and produces sparse representations of the input data, ReLU is a frequent option in CNNs. If the input is good, it returns the input; otherwise, it returns 0. Other nonlinear functions that are utilised in CNNs are sigmoid and tanh, which yield gradients close to zero when the input is big. The activation function layer is the "brain" of the CNN, where input is processed into a meaningful representation of the data. It is an essential component.
Batch Normalization Layer
In convolutional neural networks, the Batch Normalisation (BN) layer is typically used to normalise each neuron's input to have a zero mean and unit variance. This aids in the stabilisation of the learning process and avoids the issue of internal covariate shift, which arises when the distribution of inputs to a layer changes during the training phase.
BN normalises each neuron's output using the mean and standard deviation of the batch of input data and is typically used after convolutional and fully connected players.
The Batch Normalisation layer benefits CNNs in various ways:
- By decreasing the internal covariate shift and enabling for larger learning rates, BN can speed up the training process.
- BN contributes to the model's regularisation, making it less prone to overfitting.
- BN has been proven to increase CNN generalisation performance, helping them to perform better on unknown data.
- BN contributes to a reduction in the number of hyperparameters that must be tuned, such as the learning rate. As a result, the training process will be simplified, and generalisation will improve.
- BN makes a model less sensitive to the initial weight settings.
Batch Normalisation is a strong approach used in CNNs to stabilise the learning process and increase model performance. It normalises each neuron's inputs, minimising internal covariate shift and regularising the model, resulting in improved generalisation performance.
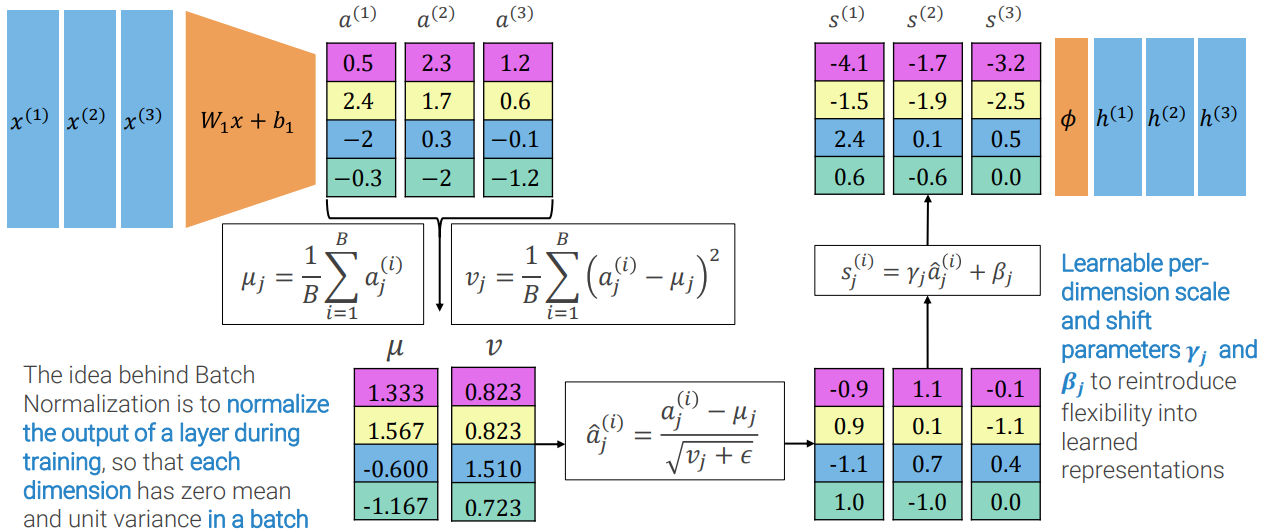
Batch Normalization process
Dropout Layer
To prevent overfitting, the dropout layer employs a regularisation mechanism. It operates by changing a percentage of input units to zero at random during each training iteration, thereby "dropping out" those units and preventing them from contributing to the forward pass.
This technique encourages the network to learn numerous distinct representations of the input, making it more resilient to changes in the input data and decreasing the likelihood of overfitting. Dropout is usually applied to a CNN's fully linked layers, although it may be applied to any layer.
Classification Layer
In a CNN, the classification layer is the last layer. This layer generates the class scores for an input picture. CNNs employ two types of classification layers: fully connected layers and global average pooling layers.
A fully connected (FC) layer is a type of neural network layer that connects all of the neurons from the previous layer to all of the neurons in the current layer. A FC layer's output is calculated by applying a weight matrix and a bias vector to the input, followed by an activation function. To generate the class scores, the FC layer is coupled to a softmax activation.
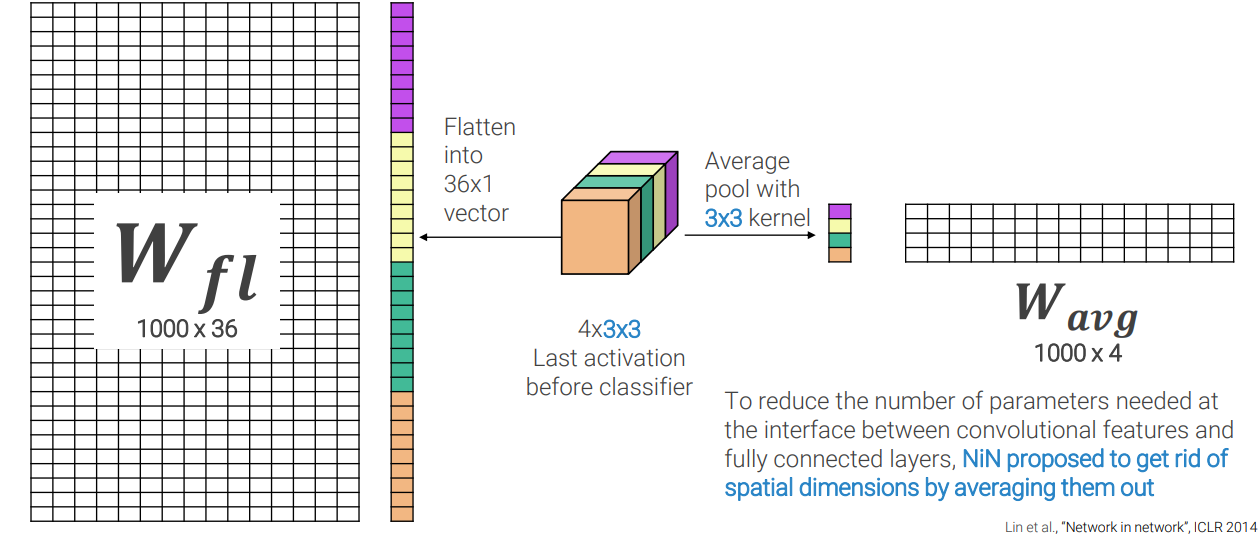
The use of fully linked layers has the benefit of allowing the network to learn complicated decision boundaries between classes. These layers, on the other hand, might cause overfitting and necessitate a huge number of parameters. Global average pooling (GAP) has been implemented to address these difficulties.
A global average pooling layer is a sort of pooling layer that decreases the spatial dimensions of feature maps by averaging their values. The GAP layer produces a 1D vector with the same size as the number of feature mappings. To generate the class scores, the GAP layer is linked to a fully connected (FC) layer using softmax activation.
GAP layers have the benefit of being less prone to overfitting and requiring fewer parameters. GAP layers, on the other hand, do not allow the network to learn complicated decision boundaries across classes.
To summarise, fully linked layers are useful for complicated decision boundaries, but they need a large number of parameters and can lead to overfitting. GAP layers are less likely to overfit, but they are less capable of learning complicated decision boundaries.
Well-Known CNN Examples
LeNet
Yann LeCun proposed LeNet for handwritten digit recognition in 1998. It is regarded as one of the earliest effective CNNs and served as the foundation for several future CNN architectures.
LeNet's architecture is made up of numerous levels, including:
- Two convolutional layers are utilised to extract features from the input picture, each followed by a max-pooling layer.
- To identify the characteristics, two completely linked layers, also called as dense layers, are employed.
The first convolutional layer has 6 5x5 filters, while the second convolutional layer has 16 5x5 filters. The max-pooling layer shrinks the spatial dimensions of feature maps by taking the maximum value in each 2x2 frame.
The first completely linked layer has 120 neurons, whereas the second layer contains 84 neurons. The last layer is a completely linked layer with 10 neurons, one for each of the digit classes.
Although LeNet is a simplistic design, it is nevertheless utilised as a starting point for many image classification problems today. LeNet, on the other hand, is not as powerful as several more contemporary designs.
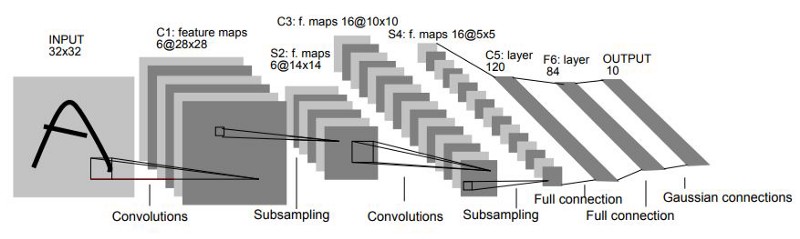
LeNet architecture (Original image published in LeCun et al., 1998)
AlexNet
In 2012, Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton proposed AlexNet. It was the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) winning model in 2012. On this test, AlexNet was the first CNN to outperform traditional, hand-crafted models.
AlexNet's architecture is made up of numerous layers, including:
- Five convolutional layers are utilised to extract features from the input image, each followed by a max-pooling layer.
- Three dense layers, which are completely linked layers, are utilised to categorise the features.
The first two convolutional layers have 96 11x11 filters, the following two convolutional layers contain 256 5x5 filters, and the last convolutional layer has 384 3x3 filters. The max-pooling layer shrinks the spatial dimensions of feature maps by taking the maximum value in each 2x2 frame. The first completely connected layer has 4096 neurons, the second fully connected layer contains 4096 neurons, and the final layer contains 1000 neurons, one for each class of the ImageNet dataset.
AlexNet pioneered numerous critical breakthroughs, including the use of the ReLU activation function, data augmentation, and dropout regularisation, that enabled it to attain state-of-the-art performance at the time. It also had far more capacity than LeNet and could learn more complicated aspects from images.
AlexNet was largely regarded as a breakthrough in the field of computer vision at the time, and it inspired many of the systems that followed.
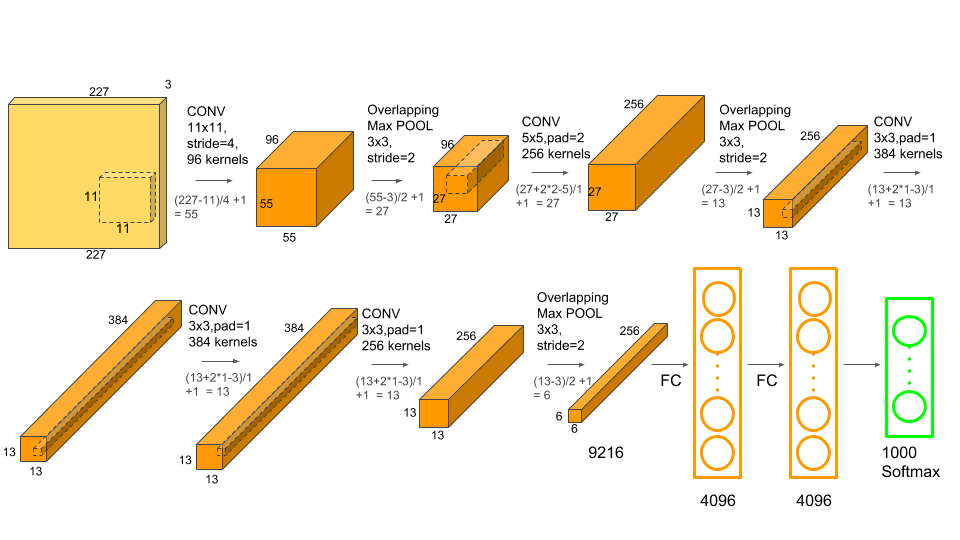
AlexNet architecture (Source: https://www.kaggle.com/code/blurredmachine/alexnet-architecture-a-complete-guide/notebook)
VGGNet
VGGNet is a convolutional neural network architecture created by the University of Oxford's Visual Geometry Group (VGG). Karen Simonyan and Andrew Zisserman introduced it in a 2014 article, and it was utilised to win the ILSVRC-2014 competition.
VGGNet is noted for its ease of use while doing well in picture classification tasks. It is made up of a convolutional and max-pooling layer stack, followed by fully linked layers. The combination of extremely tiny convolutional filters (3x3) with a very deep architecture (up to 19 layers) is the core characteristic of VGGNet. Later, this architecture was updated and utilised as the foundation for numerous computer vision applications such as object identification and image segmentation.
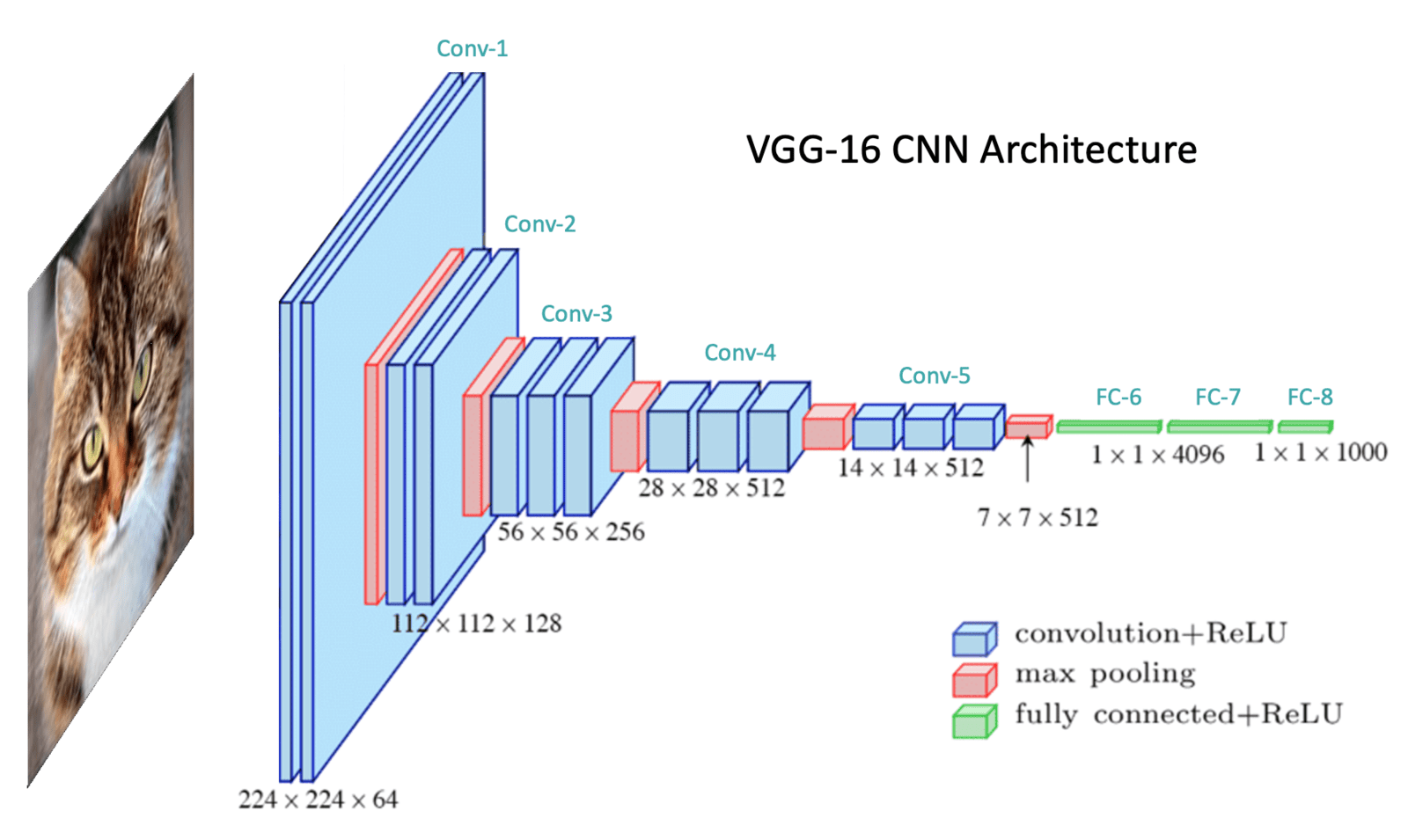
VGGNet architecture (Source: https://learnopencv.com/understanding-convolutional-neural-networks-cnn/)
ResNet
The problem of vanishing gradients, when the gradients (used for updating the parameters during training) become very tiny and training becomes sluggish, is one of the key obstacles in training very deep neural networks. ResNet (Residual Neural Network), introduced in 2015 by Microsoft Research, solves this issue by introducing the notion of "residual connections."
A residual link is a shortcut connection that allows the gradient to travel straight to prior levels by bypassing one or more layers. ResNet can now train far deeper networks than prior designs without encountering the vanishing gradient problem.
The depth of ResNet designs distinguishes them. ResNet had 152 layers at the beginning. ResNet-50, ResNet-101, and ResNet-152 are more current variants with 50, 101, and 152 layers, respectively. ResNet has grown in popularity as a backbone for a variety of computer vision applications, including object identification, semantic segmentation, and picture classification.
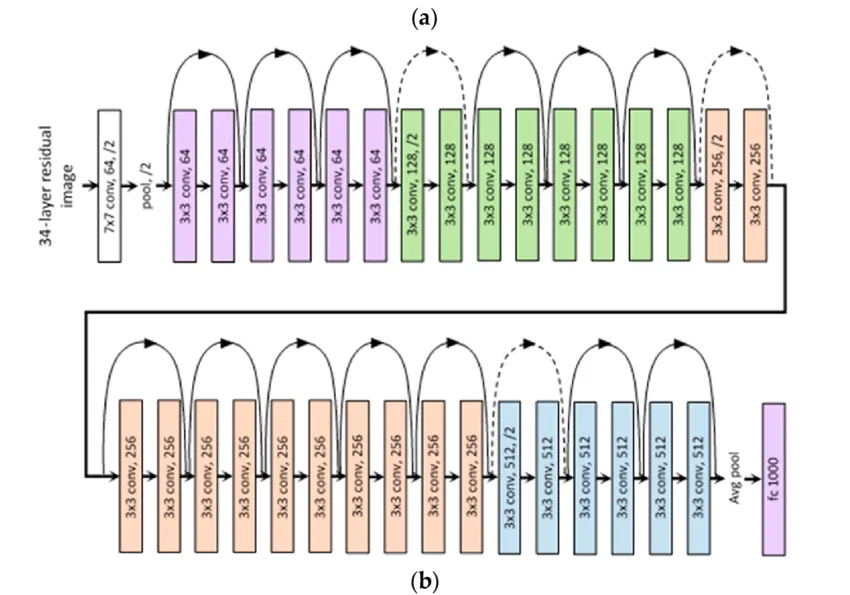
ResNet-34 Layered architecture (Source: https://medium.com/@siddheshb008/resnet-architecture-explained-47309ea9283d)
MobileNet
Google's MobileNet, released in 2017, was created primarily for usage on mobile and embedded devices with minimal computing capabilities. MobileNet use depth-wise separable convolutions to minimise parameter count and processing expense while retaining accuracy.
A depth-wise separable convolution applies a single convolutional filter to each input channel (depth-wise convolution) and then combines the results with a pointwise convolution (1x1 convolution). When compared to typical convolutional layers, this technique minimises the amount of parameters and processing required.
The MobileNet architecture is lightweight and efficient, making it ideal for use on mobile and embedded devices with limited memory and computing capacity.
There are various variations of the model, each with a different level of intricacy and accuracy. The most common versions are MobileNet V1, V2, and V3. MobileNet V3, the most recent version, is said to be the most efficient, with a good mix of accuracy and efficiency.
MobileNet has been utilised in a variety of applications, including object identification, semantic segmentation, and picture classification, as well as providing a backbone for numerous computer vision tasks, including face recognition, object tracking, and many more.
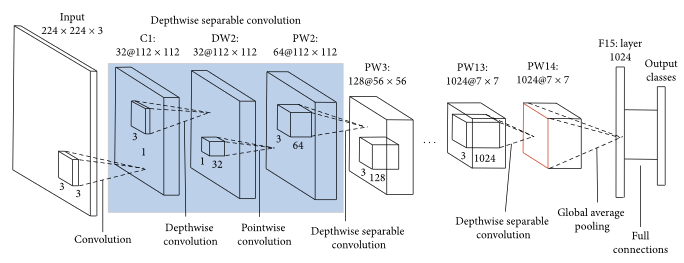
MobileNet architecture
Conclusion
Convolutional Neural Networks (CNNs) are a sort of deep learning architecture that has found widespread use in computer vision applications such as image classification, object recognition, and semantic segmentation. CNNs outperform standard computer vision approaches in various ways, including:
- Processing vast volumes of data: CNNs can learn from massive volumes of data, making them ideal for training on large datasets like ImageNet.
- Robustness to translation and rotation: CNNs can train features that are resistant to little changes in the location and orientation of objects in an image, making them ideal for tasks like object recognition and semantic segmentation.
- Transfer learning: CNNs learned on big datasets like ImageNet may be fine-tuned on smaller datasets, reducing the quantity of data and processing resources necessary to train a model for a given job.
CNNs limitation include:
- Overfitting: When the quantity of data available is restricted, CNNs are prone to overfitting, which can result in poor performance on unknown data.
- Computing cost: CNNs demand large computing resources to train and deploy, which might be a barrier to adoption on mobile and embedded systems.
- Explainability: CNNs are sometimes seen as black boxes, making it difficult to grasp how they make judgements and discover possible flaws.
Learn more about SKY ENGINE AI offering
To get more information on synthetic data, tools, methods, technology check out the following resources:
- Telecommunication equipment AI-driven detection using drones
- A talk on Ray tracing for Deep Learning to generate synthetic data at GTC 2020 by Jakub Pietrzak, CTO SKY ENGINE AI (Free registration required)
- Example synthetic data videos generated in SKY ENGINE AI platform to accelerate AI models training
- Presentation on using synthetic data for building 5G network performance optimization platform
- Working example with code for synthetic data generation and AI models training for team-based sport analytics in SKY ENGINE AI platform


