



Class-specific visualization results from Vision Transformer with attention maps.
Transformers, initially described in a Google paper titled "Attention Is All You Need" in 2017, use a self-attention mechanism to tackle sequence-to-sequence problems such as language translation and text production. According to the abstract for the article, the transformer, which is simpler in construction than its predecessor, can do away "with recurrence and convolutions entirely."
Deep learning advances have effectively adapted the transformer design for computer vision applications such as image classification, resulting in vision transformers.
What is a Transformer?
Vision transformers, unlike convolutional neural networks (CNNs), lack inductive biases such as translation invariance and locality. Despite this, vision transformers have outperformed well-established CNN models in image classification. Recent efficiency gains in data and computing needs have made vision transformers a viable and useful technique for deep learning practitioners to consider in their work.
Transformer Architecture: Ultimate guide
The original transformer architecture greatly influences the construction of vision transformers. Understanding vision transformers requires a strong understanding of transformer construction, particularly the encoder component.
This section offers an overview of the essential components of a transformer, as depicted in the picture below. While this explanation focuses on textual data, other types of input, such as flattened image patches in vision transformers, can be used as well.
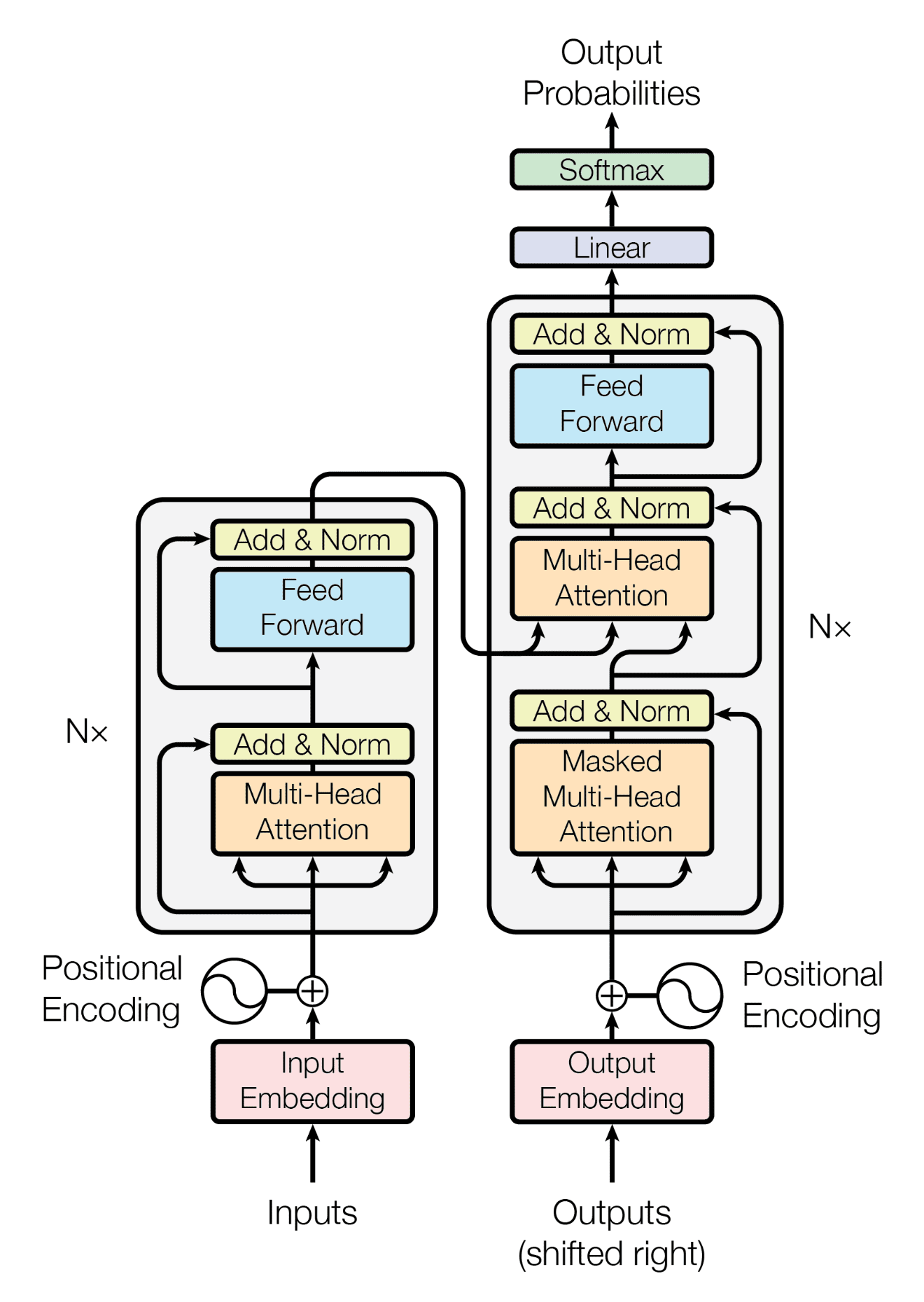
Constructing the Input
Transformers work using a sequence of tokens created from the input data. To generate the tokens, the input data, which is often text, is run through a tokenizer. The tokenizer's role is to apply rules to break down text into separate tokens. Then, for each of these tokens, a unique integer identification is assigned.
A learnable embedding matrix is indexed using the token IDs. This procedure generates an input data matrix with dimensions (N x d), where N is the number of tokens and d denotes the dimensionality of the embedding vectors. The embedding vectors serve as a numerical representation of the tokens, which are subsequently input into the transformer model, which is used to make predictions.
Typically, the transformer handles a full batch of sequence data at once, with each batch having numerous token sequences. To guarantee consistency, all sequences within a batch are padded with extra tokens (e.g., zeros or random values) to the same length (N). This allows the transformer to treat the batch as a single (B x N x d) matrix, where B is the batch size and d is the dimension of the embedding vector for each token. The padding tokens are disregarded by the self-attention mechanism, which is a critical component of transformer architecture.
Positional information is encoded in the embedded tokens before the input sequence is delivered into the self-attention mechanism. A transformer's self-attention mechanism does not naturally capture the location of each token in the sequence. Adding learnable position embeddings to each token allows the model to include positional information. This allows the transformer to comprehend the relative order of the tokens in the sequence and handle the incoming data more effectively.
The Encoder
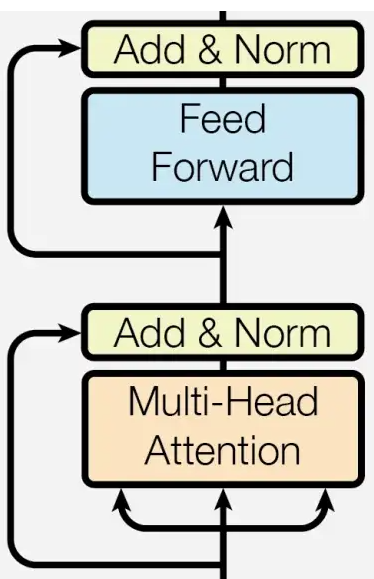
The Encoder in Transformer architecture. (Source: https://arxiv.org/pdf/1706.03762.pdf)
The transformer's encoder component is made up of numerous layers with a uniform structure. These layers contain the following elements:
- Multi-Headed Self-Attention
- Feed-Forward Neural Network
Following each of these modules is layer normalisation and a residual connection. The representation for each token is modified by sending the input sequence through these levels using the representations of other tokens in the sequence, as well as a learnt, multi-layer neural network that performs a non-linear transformation of each individual token.
When an input sequence is processed through numerous successive layers of the same structure, the resultant output sequence has a comparable length and contains context-aware representations for each token. The combined impact of normalisation, residual connection, and the numerous modules involved in the transformation process achieves this.
The Decoder
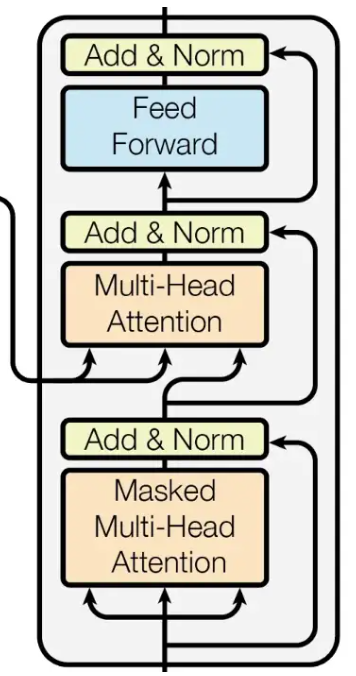
The Decoder in Transformer architecture. (Source: https://arxiv.org/pdf/1706.03762.pdf)
The decoder is made up of several identical layers. Each layer contains the following elements:
- Masked Multi-Head Attention
- Multi-Head Attention
- Feed-Forward Neural Network
Masked self-attention aids in sequence-to-sequence tasks such as language translation by preventing a model from "looking ahead" in the input sequence. This implies that in the decoder, each token is solely altered depending on the tokens that come before it in the input sequence.
Multi-head self-attention parallelizes numerous separate self-attention computations, each with its own set of parameters. This improves the representation of the input and aids in capturing various, distinct links between tokens in the sequence.
The feed-forward neural network (FFN) performs a linear transformation on the output of the multi-head self-attention component, which is then followed by activation functions like ReLU or GELU.
The FFN then changes the representations further and normalises the final output.
Finally, a residual connection is added to the layer normalisation component's output. This link aids in the resolution of the vanishing gradient problem during training, which can have a major and unfavourable influence on training results. The residual link preserves the original information and prevents overfitting.
A decoder laye is formed by the combination of these components. The decoder's ultimate output is context-aware representations of each token in the sequence.
Self-Supervised Pre-Training
Transformers were designed to do sequence-to-sequence tasks. However, their appeal and widespread use has been reinforced by their success in other challenges like as text synthesis and sentence classification. The use of self-supervised pre-training approaches using transformers is primarily accountable for the success in these challenges.
The principle of self-supervised learning has considerably aided transformer success. Self-supervised tasks, such as predicting "masked" (hidden) words in unlabeled raw text data, can be used to train transformers on massive volumes of data.
BERT popularised this pre-training strategy, which has since been adopted by several subsequent transformer models, resulting in considerable advances in natural language comprehension tests. The fine-tuning of BERT on supervised tasks, for example, produced outstanding results. This concept was eventually used in the creation of GPT-3.
While the use of self-supervised learning has had a huge influence in NLP, as of the time of writing, the same success has not yet been found in vision transformers. Despite many tries, this method has failed to provide the same results in vision-related applications as it has in NLP.
Transformers in Computer Vision
Attention mechanisms are commonly utilised in computer vision in conjunction with Convolutional Neural Networks, but there are just a few occasions where the transformer architecture has been used exclusively to solve computer vision challenges. Attention mechanisms can also be used to substitute particular components of CNNs while maintaining the general structure of the network.
Although CNNs are included in many standard computer vision models, recent advances in the area have demonstrated that pure transformer models applied directly to sequences of picture patches may do remarkably well on image classification tasks.
The Vision Transformer (ViT) model, which is based on a transformer encoder, has shown extremely competitive performance in a variety of computer vision applications such as picture classification, object identification, and semantic image segmentation. This model demonstrates the versatility of transformers in computer vision.
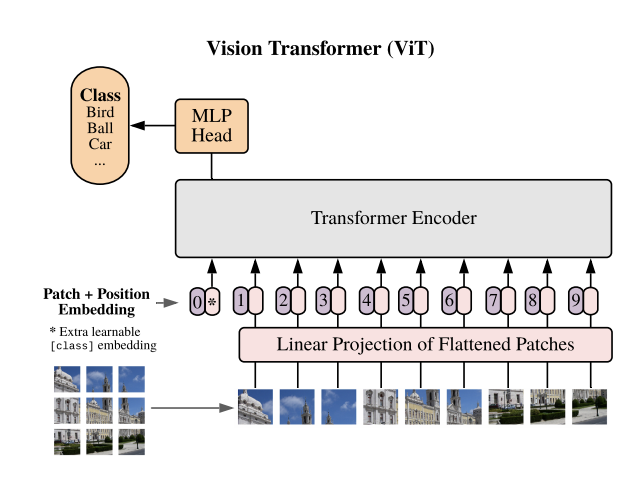
The Vision Transformer architecture. (Source: https://paperswithcode.com/method/vision-transformer)
Vision Transformer Structure
The ViT model includes a self-attention layer that allows information to be embedded globally over the entire image. The model learns to represent the relative location of the image patches during training, successfully recreating the image's structure. The transformer encoder in ViT is composed of three parts:
- Multi-Head Self-Attention Layer: This layer linearly concatenates attention outputs and employs several attention heads to train both local and global dependencies within an image;
- Multi-Layer Perceptrons: A two-layer system with a Gaussian Error Linear Unit (GELU) activation function;
- Layer Norm: Added before each block to limit the formation of new dependencies between training pictures, which aids in the reduction of training time and overall performance.
Furthermore, residual connections are designed into the ViT architecture after each block to promote information flow across the network without meeting non-linear activations. The MLP layer serves as the classification head during image classification tasks, with one hidden layer for pre-training and a single linear layer for fine-tuning.
Vision Transformer in use
Vision Transformers follows the following procedure to perform an image classification task:
- Split an image into patches (fixed sizes).
- Flatten the image patches.
- Create lower-dimensional linear embeddings from these flattened image. patches.
- Include positional embeddings.
- Feed the sequence as an input to a state-of-the-art transformer encoder.
- Pre-train the ViT model with image labels, which is then fully supervised on a big dataset.
- Fine-tune the downstream dataset for image classification.
Attention Maps: Visualizing Predictions
In the context of a Vision Transformer, "attention maps" are visual representations of the attention scores generated by the transformer's self-attention mechanism. These attention ratings define how much information from one token is utilised to affect how another token is represented.
Attention maps are created by applying the self-attention mechanism to input tokens and then visualising the attention scores that arise. These maps illustrate which tokens influence each other and give information on how the model processes the image.
We can acquire a better grasp of how the model makes predictions and discover regions where the machine is struggling to learn significant correlations between the tokens by visualising the attention maps. This data may be utilised to improve the model's performance by modifying the architecture or the training procedure.
In general, attention maps in the context of a ViT are visual representations of the relationships between tokenized image patches that might give useful information for enhancing the model's performance.
Class-specific visualization results from ViT with attention maps. (Source: https://www.researchgate.net/publication/355693348_Transformers_in_computational_visual_media_A_survey)
While the Vision Transformer architecture has significant potential for visual processing applications, its performance remains poor when trained from scratch on moderate-sized datasets like ImageNet compared to similar-sized Convolutional Neural Network alternatives such as ResNet. Despite this, ViTs have outperformed CNNs when fine-tuned or pre-trained on huge datasets, and they have higher computational efficiency.
CNN vs. Vision Transformers
The Vision Transformer is a model that handles image categorization by utilising the architecture of a transformer, which was originally created for text-based applications. Unlike Convolutional Neural Networks, which analyse images as pixel arrays, ViT divides the image into fixed-sized patches, which are then implanted as visual tokens. The model then employs positional embeddings to interpret the patches as sequences, which are subsequently fed into a Transformer encoder for image class label prediction.
The performance of a Convolutional Neural Network and a Vision Transformer is dependent on various aspects, including the quantity of the dataset, the difficulty of the job, and the model architecture.
When trained on big datasets, Vision Transformer outperforms state-of-the-art CNNs in accuracy despite demanding 4x the processing resources. Transformers' successful use in NLP tasks has now been extended to images, where ViTs have shown to be extremely effective in image identification.
In terms of computing efficiency during pre-training, the Vision Transformer model surpasses Convolutional Neural Networks. However, because ViT lacks the inductive bias found in CNNs, it is more reliant on regularisation or data augmentation approaches when working with smaller datasets. When utilising Vision Transformers, further model regularisation or data augmentation procedures may be required to achieve optimal performance.
CNNs are well-known for their powerful spatial information processing capabilities, which make them ideal for image classification jobs requiring local feature extraction. They do this by using convolutional filters on the input image to learn local properties like edges, corners, and textures.
ViTs, on the other hand, are built to handle large-scale datasets, and they process the tokenized image patches using the transformer architecture, which was initially created for NLP applications. ViTs can capture long-range relationships between tokens, allowing them to collect broader image information.
When trained on very big datasets, such as ones containing over 14 million images, a ViT can outperform a CNN in terms of performance. However, if the dataset is small, known models like as ResNet or EfficientNet are frequently more successful.
This is due to the fact that ViTs contain a high number of parameters that might be difficult to optimise on smaller datasets, whereas CNNs are often more successful in these situations. Finally, the decision between a CNN and a ViT will be determined by the job at hand as well as the available resources, such as the size of the dataset and computer capacity.
Models Based on Transformers
GPT
GPT is a language model created by OpenAI that employs generative training and does not require labelled data for training. It forecasts the likelihood of a word sequence in a language. As of February 2023, there are four GPT versions: GPT-1, GPT-2, GPT-3, and GPT-3.5.
The GPT-1 model is trained in two stages, starting with unsupervised pre-training on a huge corpus of unlabeled data using the language model objective function. This is followed by supervised fine-tuning of the model with task-specific data on a given task. The transformer decoder design underpins the GPT-1 concept.
The primary goal of GPT-2 is to generate text. GPT-2 uses an autoregressive technique to create text and trains on input sequences with the goal of predicting the next token at each point in the sequence. The model is constructed of transformer blocks, with an emphasis on the attention mechanism. GPT-2 has fewer dimensional parameters than BERT (explained further below). GPT-2, on the other hand, has more transformer blocks (48 blocks) and can handle longer sequences.
GPT-3's architecture is identical to GPT-2's, except it features more transformer blocks (96 blocks) and is trained on a bigger dataset. Furthermore, the sequence length of the input phrases in GPT-3 is double that of GPT-2.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a deep-learning model created by Google for natural language processing applications such as text categorization and inference. An encoder-only transformer learns contextual representations of words in a given text corpus as part of the architecture.
BERT employs self-supervised pre-training approaches, in which the model learns to predict masked tokens in input text by using bidirectional representations of the words surrounding the masked tokens. BERT can learn contextual links between words in a given text by collecting both their left and right context.
BERT may be fine-tuned on specific NLP tasks, such as sentiment analysis or question answering, after being pre-trained, by utilising a task-specific output layer on top of the pre-trained representation layer. The fine-tuning method enables the model to adjust pre-trained weights to the target task while learning from labelled data unique to the task.
BERT's capacity to learn and remember contextual associations between words in a given text has resulted in considerable advances over previous NLP models, and it is now frequently utilised in many NLP applications.
DALLE-2
DALL-E 2 is an OpenAI transformer-based generative model. It can generate a wide range of images with high resolution from written inputs. DALL-E 2's design is made up of a 12-layer transformer with multi-head self-attention and feed-forward modules on each layer.
The model takes a textual description as input and converts it into a dense vector representation using an embedding layer. This vector is then sent through the transformer layers to produce a representation that accurately represents the context of the textual description.
To construct a picture, the output of the final transformer layer is reshaped and passed through multiple thick layers. DALL-E 2 trains the model using a mix of ImageNet features and an L2 loss function. The L2 loss is used to compare the produced and target images, and ImageNet features are employed to ensure semantic coherence.
In summary, DALL-E 2 generates a dense representation of the textual description via the transformer layers and then transforms this representation into an image via many thick layers. The model is trained to produce pictures that are semantically coherent and visually comparable to the target image.
Conclusion
Transformers are a sort of neural network design frequently used in Natural Language Processing jobs. They are based on self-attention processes, which allow the network to examine all elements in the input sequence's interactions.
The Encoder-Decoder design is the most common transformer architecture, however there are additional encoder-only and decoder-only varieties used to solve specific challenges. Self-supervised pre-training of transformers on enormous volumes of textual data has resulted in considerable increases in NLP task performance.
Transformers have showed promise in computer vision for tasks like as object identification and semantic segmentation, while the use of self-supervised pre-training has not been as effective as in NLP. Nonetheless, the design is still being investigated and improved in the computer vision field suggesting improvements to the original transformer architecture to better fit vision AI requirements.
Learn more about SKY ENGINE AI offering
To get more information on synthetic data, tools, methods, technology check out the following resources:
- Telecommunication equipment AI-driven detection using drones
- A talk on Ray tracing for Deep Learning to generate synthetic data at GTC 2020 by Jakub Pietrzak, CTO SKY ENGINE AI (Free registration required)
- Example synthetic data videos generated in SKY ENGINE AI platform to accelerate AI models training
- Presentation on using synthetic data for building 5G network performance optimization platform
- Working example with code for synthetic data generation and AI models training for team-based sport analytics in SKY ENGINE AI platform


